PROPEL: Breaking the Solver Bottleneck in Task-Generator RL
The Solver Bottleneck
Reinforcement learning on verifiable rewards has carried the current generation of reasoning and agentic models, but progress under this recipe is gated by task supply. As policies improve, fixed task distributions saturate; further gains require harder tasks that remain discriminative at the capability frontier. Hand-curated benchmarks cannot keep pace, and naive synthetic generation yields tasks that are trivially solvable or ill-posed.
The approach we are taking at Vmax is to train an open-ended task generator with RL, rewarding it for tasks that are valid and appropriately difficult for a target solver, the model or agent that attempts them. In this work only the generator is trained and the solver stays fixed; the goal is to make exactly this training step tractable. In previous work we co-evolve teacher and student through asymmetric self-play; a version of PROPEL that fully closes that loop is future work.
Training task generators is difficult because a reliable estimate of the solve rate requires many solver attempts. In agentic settings this is prohibitive. A single SWE rollout involves repository navigation, tool calls, and test execution, and can take tens of minutes. Embedding many such rollouts per candidate inside generator RL is intractable whenever the verifier is an expensive stochastic agent; in math and code the trials are cheaper, but the cost and variance remain.
PROPEL, Probe Rewards for Optimizing Problems at the Edge of Learning, breaks this bottleneck. A small activation probe, trained once on solver-labeled tasks, predicts the target solver's pass rate from a single forward pass through a frozen reference model. This probe replaces the solver in the RL loop (Figure 1). Across math, code induction, and software engineering (including a 27B agent on unseen repositories), the probe-trained generator produces tasks at the learnable frontier at roughly double the rate of the base generator.
What Makes a Good Task Generator?
We evaluate generators on three axes:
- Validity: the fraction of generations that are well-formed (programs that parse and run).
- Utility: the fraction at the learnable frontier, i.e. with solve rate inside a target band.
- Diversity: coverage of the task space rather than repetition of a few patterns.
Utility uses a strict band. A task is useful if its mean solve rate over K solver attempts lands inside a target band:
For math and AZR the band is 1–3 successes out of 8 attempts (a=1/8, b=3/8); for SWE, the optimal solve rate band is from a=1/3 to b=2/3. Tasks the solver always fails are too hard, tasks it always solves are saturated; only the middle band earns credit. The probe is trained against this binary label, and every reported result re-scores fresh generations with the actual solver; the probe score is never the reported outcome.
PROPEL
PROPEL replaces in-the-loop solver rollouts with a single forward pass through a frozen reference model and a small activation probe. We collect a one-time labeled corpus of (task, solver-outcome) pairs and train the probe on the reference model's hidden states to predict the target solver's pass rate; gated by a cheap validity check, the probe then serves as the RL reward for the task generator (Figure 2).
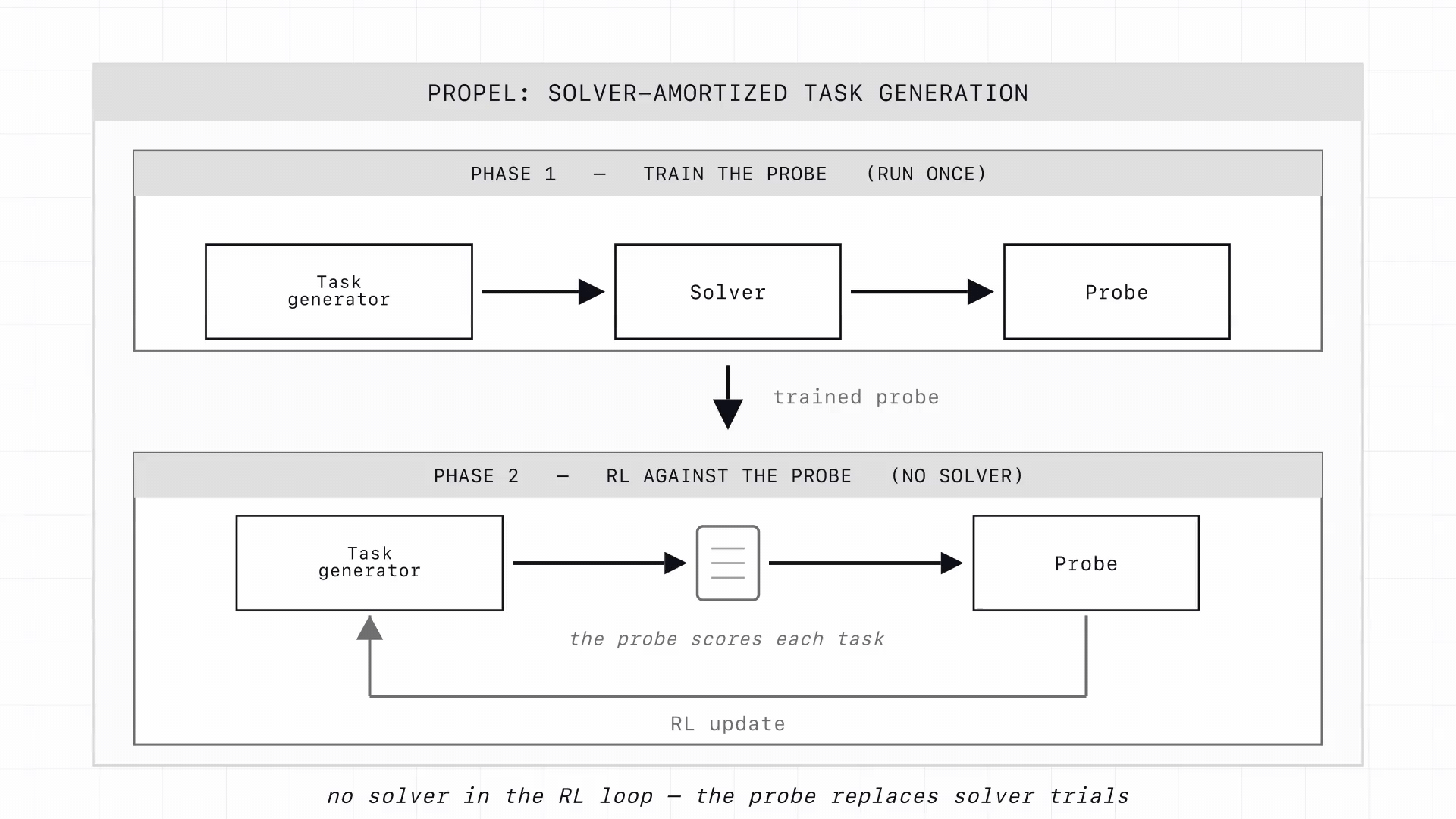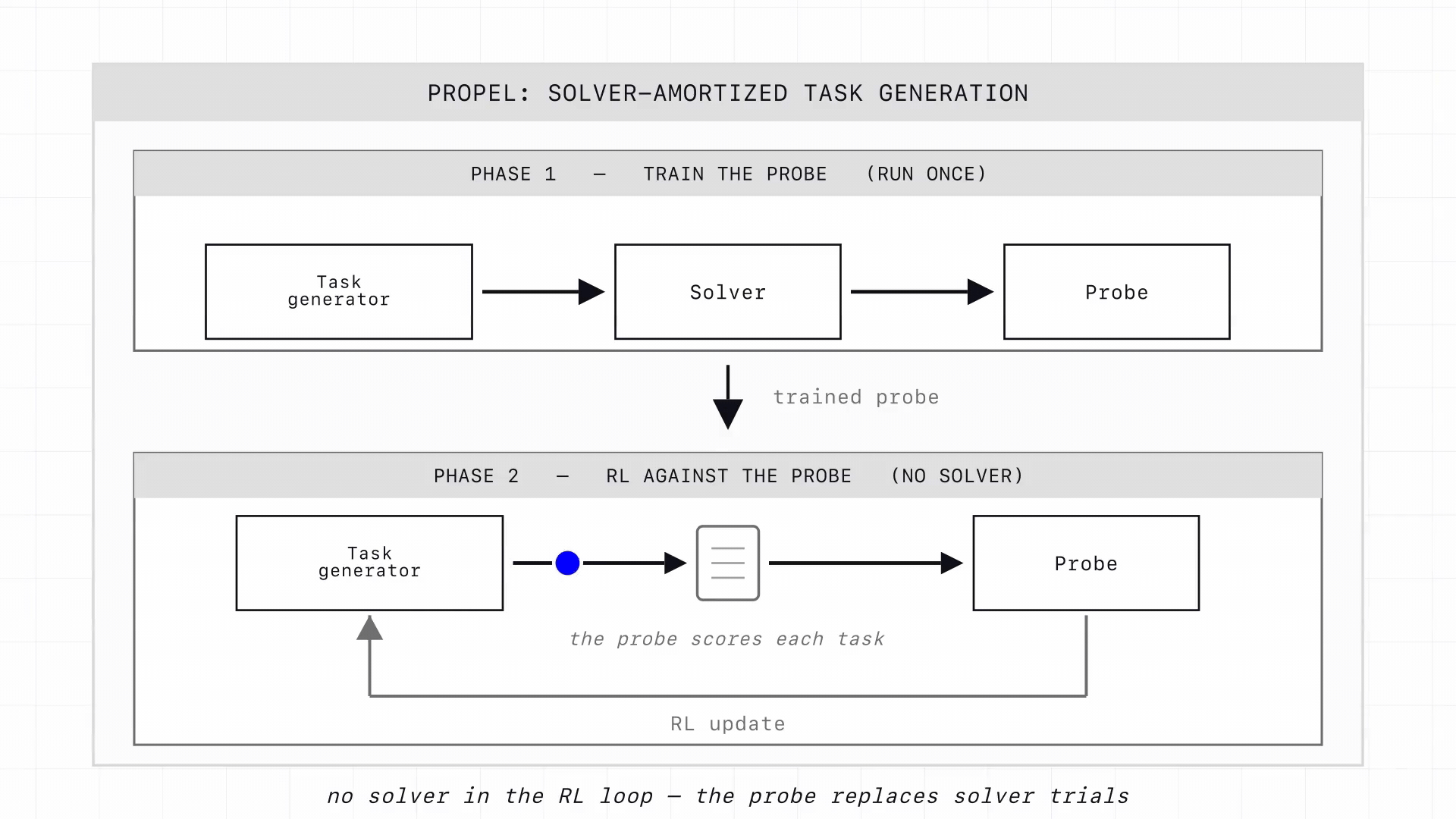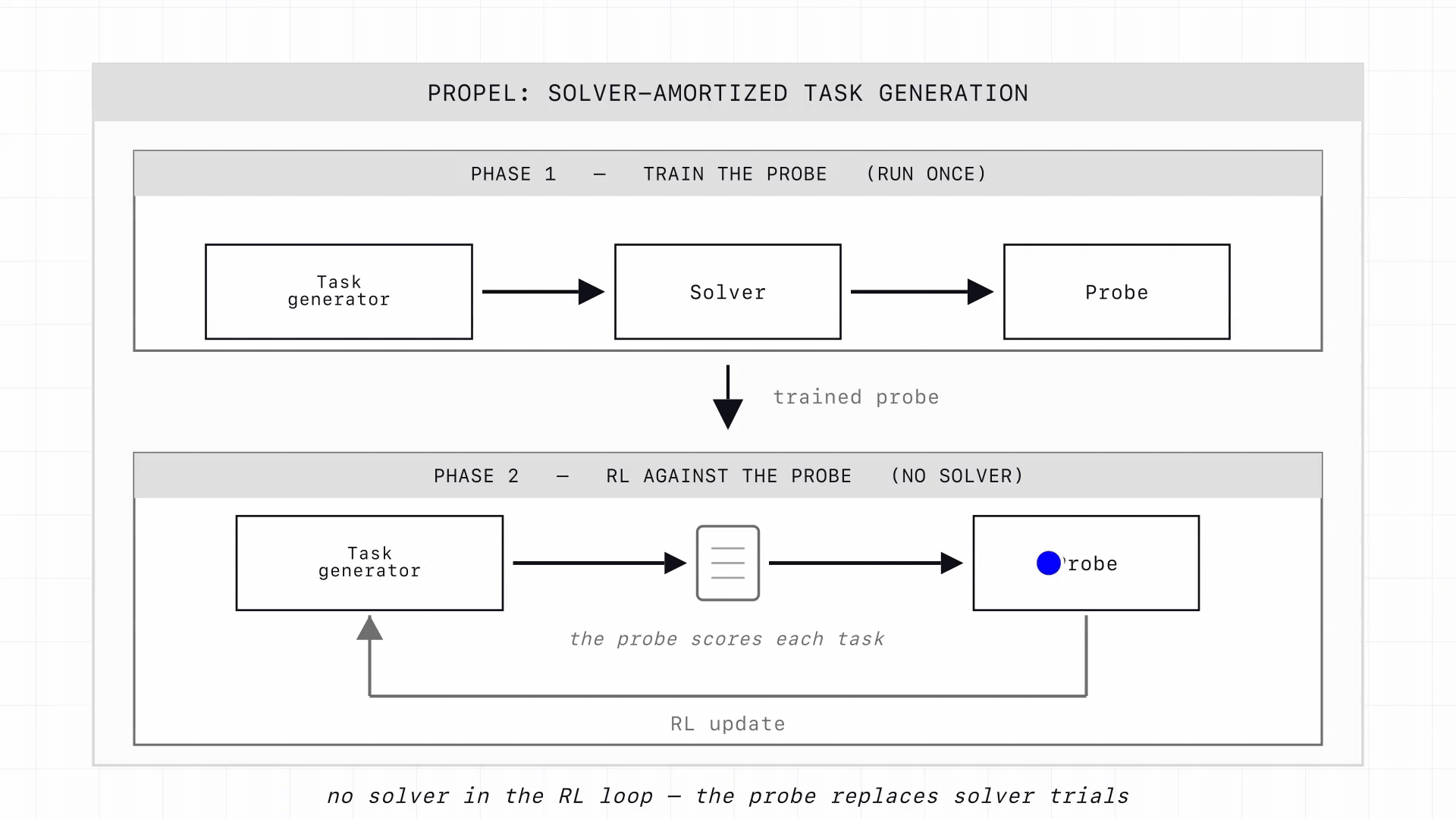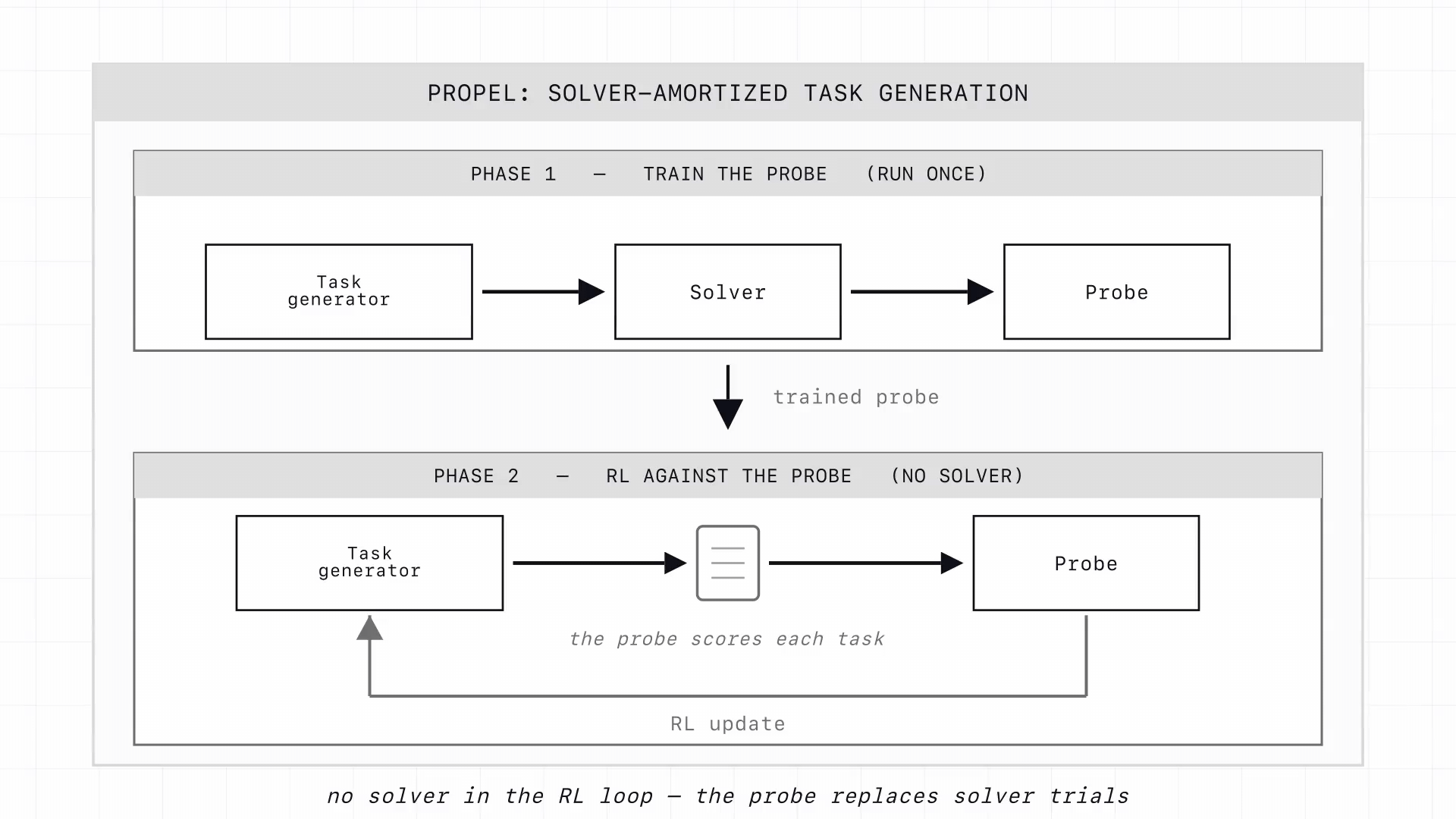
This exploits a well-documented property of language models: quantities of interest are often represented internally even when the model cannot act on them reliably at generation time. If a task's well-formedness, solvability, and difficulty are decodable from hidden states, the probe provides a dense, near-free reward long before any solver rollout would confirm it.
The probe reads from a frozen reference copy of the base generator, not from the policy being updated: the reward depends only on the rendered task, so the policy cannot inflate it by shifting the activations the probe reads. Validity is a gate, not a score: invalid generations receive a fixed penalty, and only valid tasks are scored by the probe.
The validity check 𝒲 is sandbox-runnable for code, oracle-validated for math, and verifier-passing for SWE.
The labeled corpus still requires solver rollouts, but the cost is paid once and amortized over all subsequent generator training. On AZR (Absolute Zero Reasoner, the code-induction setting in Table 1), PROPEL spends 22,592 offline solver trials to label the probe and then runs RL with no solver in the loop; the solver-in-the-loop baseline spends 53,664 trials in a single 30-step run, requires a co-located solver server, and ends with half the utility gain. The asymmetry grows with solver cost: in SWE, labeling one bug takes K=3 agent runs in a Docker sandbox, and no comparable solver-in-the-loop run is feasible at all.
| Method | Signal cost / task | Solver trials (online / offline) | Utility ↑ (lift) | Valid ↑ |
|---|---|---|---|---|
| Base (untrained) | n/a | 0 / 0 | 10.1 | 66.5 |
| Solver-in-the-loop | 8 solver trials | 53.7k / 0 | 14.04 (+3.95) | 90.66 |
| PROPEL | 1 probe eval | 0 / 22.6k | 19.95 (+9.86) | 90.85 |
Table 1. Code induction, targeting a Qwen2.5-3B solver at the 1–3@8 band. PROPEL more than doubles the utility lift of solver-in-the-loop (SIL) training at matched validity, while spending its solver trials once, offline, to label the probe.
Results
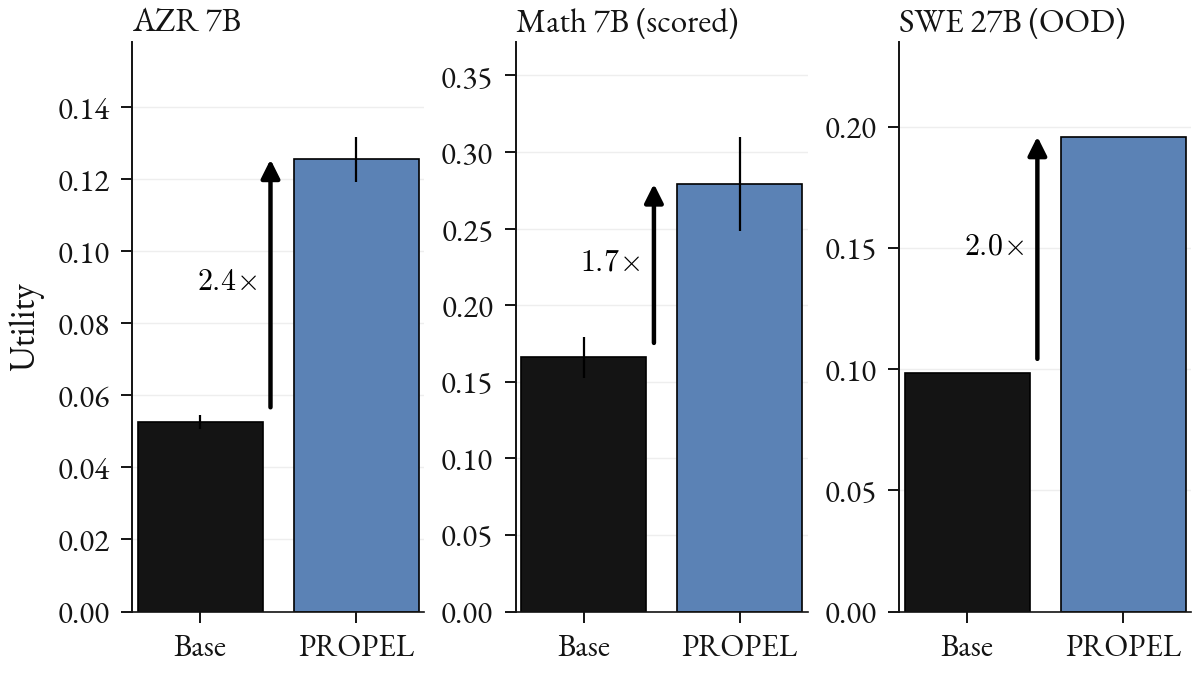
Figure 3. Frontier-band utility, base vs PROPEL: 2.4× on AZR and 1.7× on math (7B solvers), 2.0× on SWE (27B, unseen repositories).
Across math, code, and SWE, PROPEL roughly doubles the rate of frontier-band tasks (Figure 3, Table 2). On code induction, the frontier rate rises from 10.1% to 20.0% against a Qwen2.5-3B-Instruct solver and from 5.3% to 12.6% against Qwen2.5-7B-Instruct. On math, among tasks that pass a strict multi-oracle well-posedness filter, the frontier yield rises by +17 points against the 3B solver and +11 points against the 7B solver.
| Method | Solver | Utility ↑ | Valid ↑ | Self-BLEU ↓ | Distinct-3 ↑ | Top-topic ↓ |
|---|---|---|---|---|---|---|
| AZR | ||||||
| Base | 3B | 0.101 | 0.665 | 0.711 | 0.376 | 0.318 |
| Single probe | 3B | 0.200 | 0.909 | 0.809 | 0.266 | 0.735 |
| Ensemble WCO | 3B | 0.173 | 0.835 | 0.714 | 0.360 | 0.685 |
| Base | 7B | 0.053 | 0.675 | 0.720 | 0.369 | 0.293 |
| Single probe | 7B | 0.125 | 0.883 | 0.734 | 0.346 | 0.674 |
| Ensemble WCO | 7B | 0.098 | 0.846 | 0.700 | 0.377 | 0.535 |
| Math | ||||||
| Base | 3B | 0.247 | 0.966 | 0.631 | 0.505 | 0.605 |
| Single probe | 3B | 0.419 | 0.960 | 0.708 | 0.387 | 0.751 |
| Base | 7B | 0.166 | 0.966 | 0.631 | 0.505 | 0.605 |
| Single probe | 7B | 0.279 | 0.957 | 0.652 | 0.464 | 0.516 |
| SWE | ||||||
| Base | 27B | 0.218 | 0.777 | 0.778 | 0.312 | 0.737 |
| Single probe | 27B | 0.266 | 0.804 | 0.882 | 0.226 | 0.694 |
| Base (OOD) | 27B | 0.098 | 0.836 | 0.811 | 0.085 | 0.605 |
| Single probe (OOD) | 27B | 0.196 | 0.751 | 0.898 | 0.093 | 0.718 |
Table 2. Main results. Bold marks the best method per metric within each comparison group. Utility is the frontier rate; Self-BLEU-3, Distinct-3, and top-topic measure diversity. "Single probe" is standard PROPEL, "Ensemble WCO" the mitigation from Mode Collapse below, and OOD the 11 unseen repositories.
The SWE result is the most informative, because nothing in the pipeline changes as the agent scales. The same recipe (frozen reference, activation probe, validity gate) delivers 9.8% → 19.6% on 11 held-out repositories never seen during generator RL or probe training, with a 27B multi-turn bash agent serving as both the generator and the target solver. The gain transfers out of the probe's training distribution and out of the RL training distribution simultaneously: the activations are not memorizing repositories, they encode whether a task lies at the solver's learnable edge.
PROPEL also changes what the bugs look like. On unseen repositories the base generator mostly produces bugs that are too easy: 60.7% of its valid bugs are solved 3/3, versus 41.6% on its training repositories. PROPEL cuts that rate to 13.5% and concentrates mass in the target band. The edits remain single lines, but they land at behavior-relevant locations and break more tests: the median number of failing tests per usable bug rises from 2 to 5.
Cross-Family Transfer
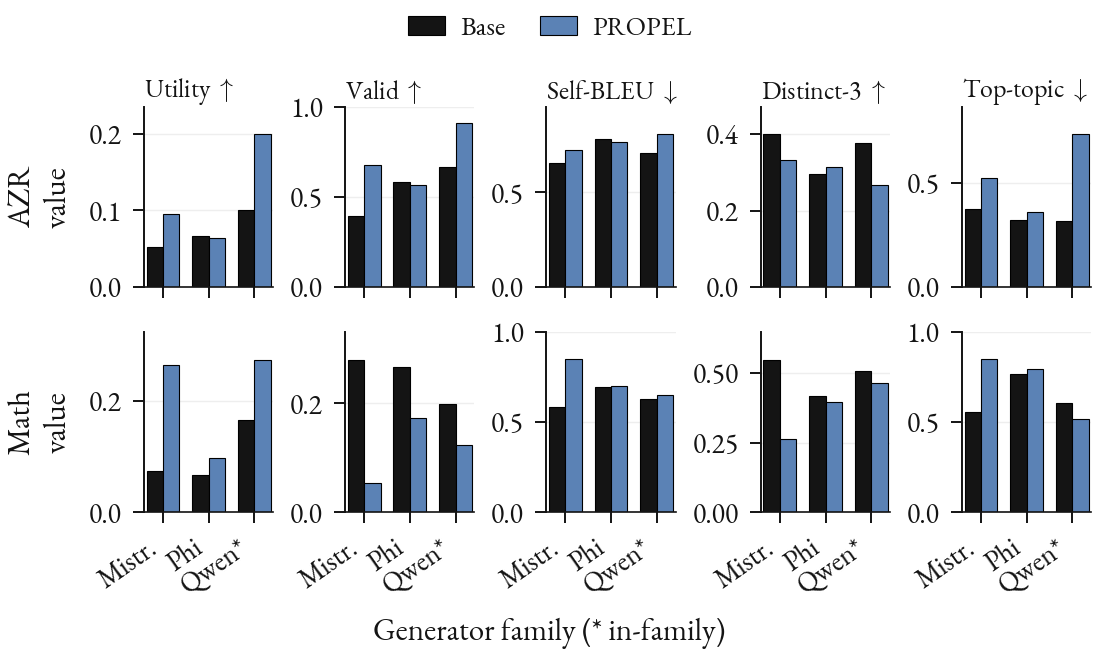
Figure 4. A probe trained on Qwen activations rewarding Mistral and Phi policies. The utility lift transfers.
Does the probe only work for the model family it was trained on? To find out, we keep the probe and the Qwen3.5-4B reference model fixed and swap the trainable policy to Mistral-7B-Instruct-v0.3 or Phi-3.5-mini-instruct, inheriting all hyperparameters from the in-family run, with no per-family tuning at all. The transfer holds up well (Figure 4). On AZR, Mistral's utility nearly doubles from 5.2% to 9.6% and its format validity rises from 39.6% to 67.4% within 30 steps; on math, its utility more than triples from 7.4% to 26.4%. Phi improves too, though more modestly, and the math Mistral run gives up some diversity that per-family tuning would likely recover. A probe trained on one family's activations can reward a completely different family's policy, without new labels or retraining: the utility signal is a property of the task as represented by the reference model, not of the policy being trained.
Mode Collapse and a Mineable Failure Mode
Optimizing against any fixed learned proxy invites reward hacking, and PROPEL is no exception. Single-probe RL on AZR coding tasks with the 3B solver concentrates roughly 74% of generated tasks on one semantic topic (sorting_order): the generator finds a high-reward region of task space and stays there. Some narrowing is expected, since the target band is itself a narrow slice of task space, but this degree of concentration gives up diversity we would like to keep.
We study two mitigations. Worst-case optimization over a probe ensemble (WCO) rewards the minimum logit across two probes instead of a single probe's logit. On AZR it reduces top-topic concentration from 0.67 to 0.54 (7B solver) and from 0.74 to 0.69 (3B solver) while retaining most of the utility lift. Adversarial probe co-evolution goes further: valid tasks that the probe scores as useful but whose true solve rate falls outside the band are false positives, and we mine them as negatives for an auxiliary probe that constrains the reward. In a first study on AZR this recovers most of the utility and validity gains without the semantic collapse, suggesting the probe's mistakes carry enough signal to train the next probe.
Outlook
Verifiable rewards have carried the current generation of reasoning and agentic models, but the supply of cheap verifiers is finite, and the bottleneck is shifting to producing the right tasks at the right time. Solver-in-the-loop generator training is the most direct approach, but it is intractable in agentic regimes. PROPEL replaces that inner loop with an offline labeling pass and a single forward pass through a frozen reference: the reward is read from internal representations instead of measured by running the solver. The probe is not the true objective and we never report it as one; it is a stand-in good enough to make optimizing a task generator tractable when the verifier is a tool-using agent.
The direction we find most promising is open-endedness. In this work the frontier is static: the solver is fixed and the generator learns one target band. In a full closed loop the solver trains too and the frontier moves. Conditioning the generator on recently attempted tasks turns the static target into a moving one, with proposer and solver co-adapting in asymmetric self-play; this inner-outer loop is expensive to optimize jointly but becomes tractable once its dominant cost, solver rollouts, is amortized by a probe. Proposing intermediate goals rather than full tasks would extend generator RL to domains with no ground-truth verifier at all. In both cases, cheap signal from model internals is what makes the loop affordable.
Interested in our work? Join us.