unix-ctf: Procedural Environments for Unix-Competence Reinforcement Learning
Terminal agents are usually described as models that can use a shell. But "using a shell" hides two different skills.
One skill is general programming through a terminal. For example, writing a Python script, running tests, editing files, or compiling a small program. The shell is the interface, but the hard part is still ordinary programming.
The other skill is Unix competence. An agent needs to understand how the operating system, filesystem, shell, and file formats expose information. A flag stored in an extended attribute will not show up in ls -l, stat, file, or a recursive grep over file contents. In this case, writing a Python program is not the best approach. Instead, an agent should know that the data lives in an inode side channel and ask for it with getfattr.
Current terminal benchmarks are often biased toward programming tasks. If they do measure Unix competence, they often do so indirectly. A model that is strong at Python but weak at Unix can still solve a meaningful fraction of terminal tasks. The reverse skill profile is tested less often. This makes it hard to tell whether a training pipeline is teaching models to operate a Unix system, or simply teaching them to write code while standing inside one.
unix-ctf is our attempt to isolate the Unix side. It procedurally generates capture-the-flag tasks inside fresh Linux containers. Each task hides a short token, such as flag{a3b1c9...}, using a single Unix feature. The agent has to recover the flag by discovering and using that feature.
The flag can be verified mechanically, and because the hiding technique can be tied to a specific OS, shell, or file-format feature, the task surface targets Unix competence directly.
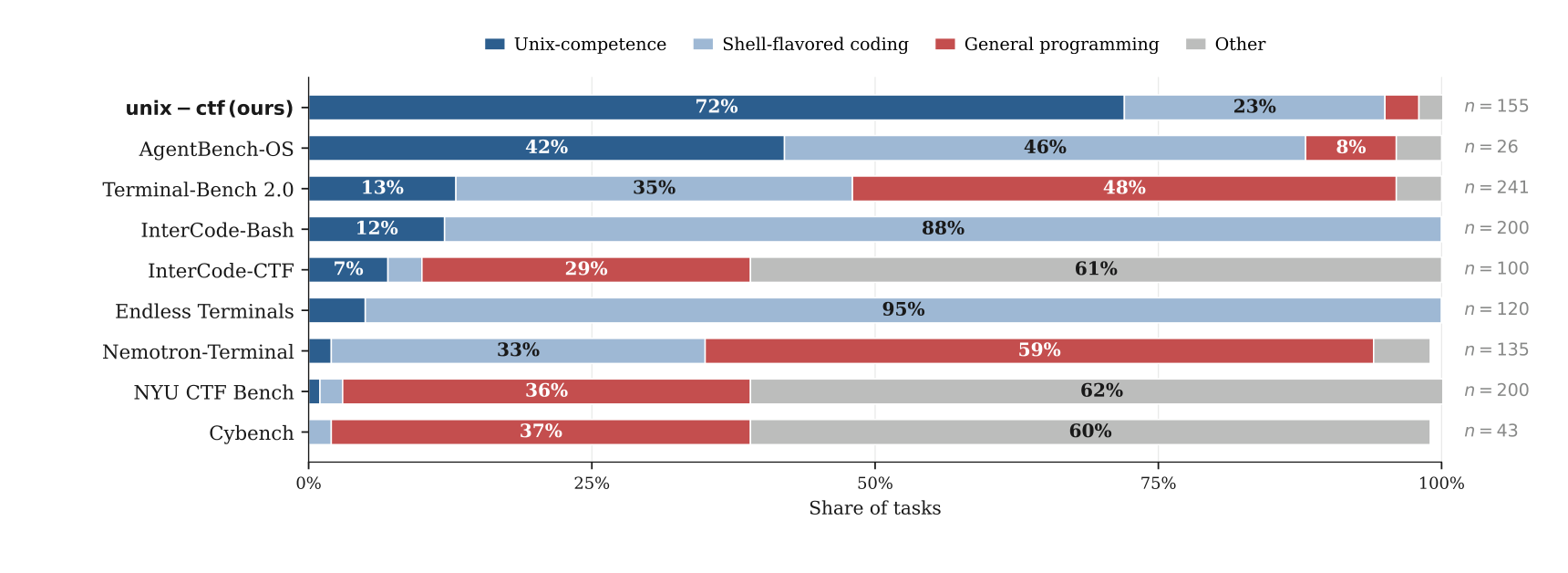
Terminal benchmarks often mix Unix competence, shell-flavored coding, and general programming. unix-ctf shifts the distribution toward Unix-specific skills.
Unix Competence
We call a task Unix competence when success depends on an OS, shell, or file-format feature with no clean analogue in ordinary general-purpose programming.
Extended attributes are one example. ELF build IDs, X.509 custom object identifiers, pre-epoch modification times, file capabilities, named pipes, Unix sockets, shell functions, systemd drop-ins, and /proc state have the same shape.
A programming language can wrap these features, but Unix knowledge is still required to complete the task. os.getxattr is still a wrapper around the getxattr(2) system call. An agent has to know that the feature exists and that it is the right access path.
unix-ctf shifts the weight toward the parts of Unix that are easy to miss: filesystem metadata, binary formats, shell state, process and IPC primitives, service configuration, logs, certificates, archives, encodings, and serialization formats.
Building the Technique Library
Vmax's research agenda is concerned with agents setting their own objectives and tasks, rather than relying on manual prompts. We continue this with unix-ctf's technique library, a portable way to hide and recover a flag using a Unix feature.
Each technique enters the library through an offline harvest pipeline. A frontier model first explores a target technique inside a pre-built Linux container and produces a candidate hiding procedure plus a recovery command. Then the system checks two things mechanically.
First, the planted flag must not appear as plaintext anywhere on disk. A simple recursive search should fail to find it. Second, the recovery command must print the flag and exit successfully.
If a candidate task passes these checks, a smaller model rewrites the planting procedure into a parameterized script pair: plant.sh, which accepts a target directory and flag, and recovery.sh, which accepts a target directory and recovers the flag. Finally, those scripts are re-run in a fresh directory with a fresh flag. This catches a common failure mode where the model accidentally hardcodes the original path or original token.
The final step canonicalizes surviving variants into distinct technique IDs. Across the run reported in the paper, 656 of 750 raw attempts survived to portable variants, an 87.5% end-to-end yield. After deduplication, those became 441 variants and 155 canonical technique identifiers.
As tasks are mined from our technique library, candidate tasks convert into our full taskset at a high yield. Alternative approaches ask a model to generate a Dockerfile, setup script, planting logic, and tests from scratch for every task. An error in any of these steps makes a task invalid. unix-ctf keeps the infrastructure fixed and asks the model only for the hide-and-find logic. Under the same checks, a reproduction of the full-container generation style used by Endless Terminals, an exciting recent approach to terminal task generation, reached 17.5% portability.
The bidirectional contract also matters. A generated task has to be solvable, but it also has to be non-trivial. Checking only that some solver can recover the answer does not prove the flag was actually hidden. Checking only that the flag is not present in plaintext does not prove the task is recoverable. unix-ctf requires both.
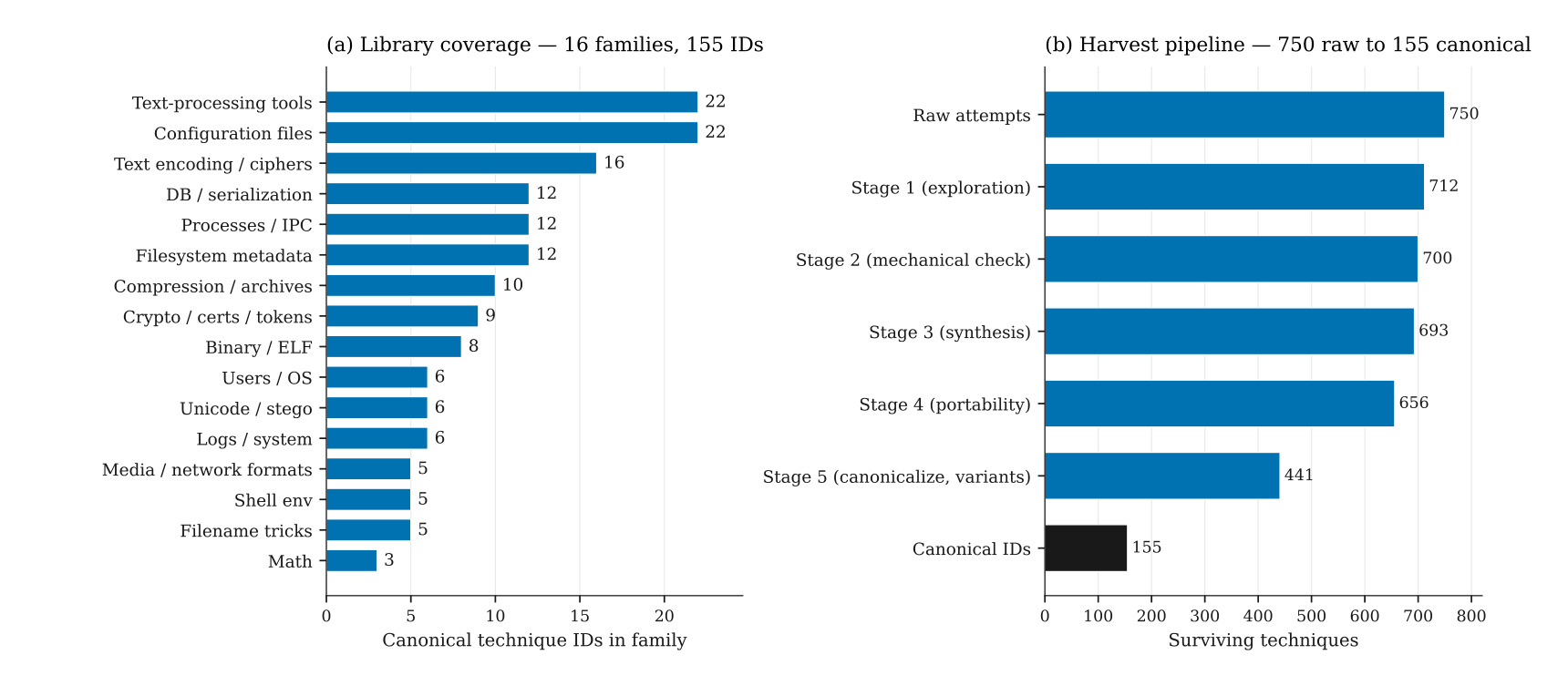
The library spans sixteen Unix-skill families, and the harvest pipeline turns 750 raw attempts into 155 canonical technique IDs.
What the Library Covers
The 155 canonical techniques span sixteen broad families.
Some are familiar Unix surfaces such as configuration files, text-processing tools, encodings, ciphers, compression, archives, and shell environment state. Others are more distinctive including filesystem metadata, processes and IPC, binary and ELF internals, certificates, tokens, logs, system state, database formats, media metadata, and user or OS account artifacts.
Every canonical technique has a short recovery path, typically one to five shell commands. That constraint keeps the tasks focused on measuring specific Unix competencies. The point is not to build a very large program. Instead, an agent must discover the right Unix strategy and use it.
This also gives the generator a reusable training surface. Once the library exists, the environment can instantiate many fresh tasks by changing target directories, flags, server roles, and surrounding filesystem context while preserving the underlying Unix skill.
Multi-Flag Environments
During training, unix-ctf does not put one flag in one container. It plants eight flags at a time.
Each environment starts from a pre-built ctf-base container. The generator can dress it as one of seven plausible server roles, such as a webserver, database, devbox, CI/CD machine, mailserver, monitoring host, or gateway. These roles add noise to the environment, which an agent would be expected to see in deployment. Users, hostnames, service configs, logs, shell histories, certificates, and directories in the environment inject noise, with the aim of making unix-ctf-trained agents more robust to conditions they would see in real Unix systems.
For each of eight sampled techniques, the generator chooses a target directory, creates a fresh flag, runs the corresponding plant.sh, records the manifest, and deletes the planting script so the agent cannot simply read it back.
The eight-flag design is a pragmatic choice to provide more granular feedback to RL agents being trained. If a container contains only one flag, early rollouts usually get zero reward, making learning difficult. With eight independent flags, a rollout can partially succeed. The reward can distinguish a model that found two flags from one that found none, and group-relative training has more useful variation to learn from.
The scheduler keeps a rotating pool of fifty techniques. Each batch samples from that pool, then removes the easiest techniques by solve rate and replaces them with less-seen ones from the rest of the library. Over forty batches, most of the 155-technique library cycles through the training stream.
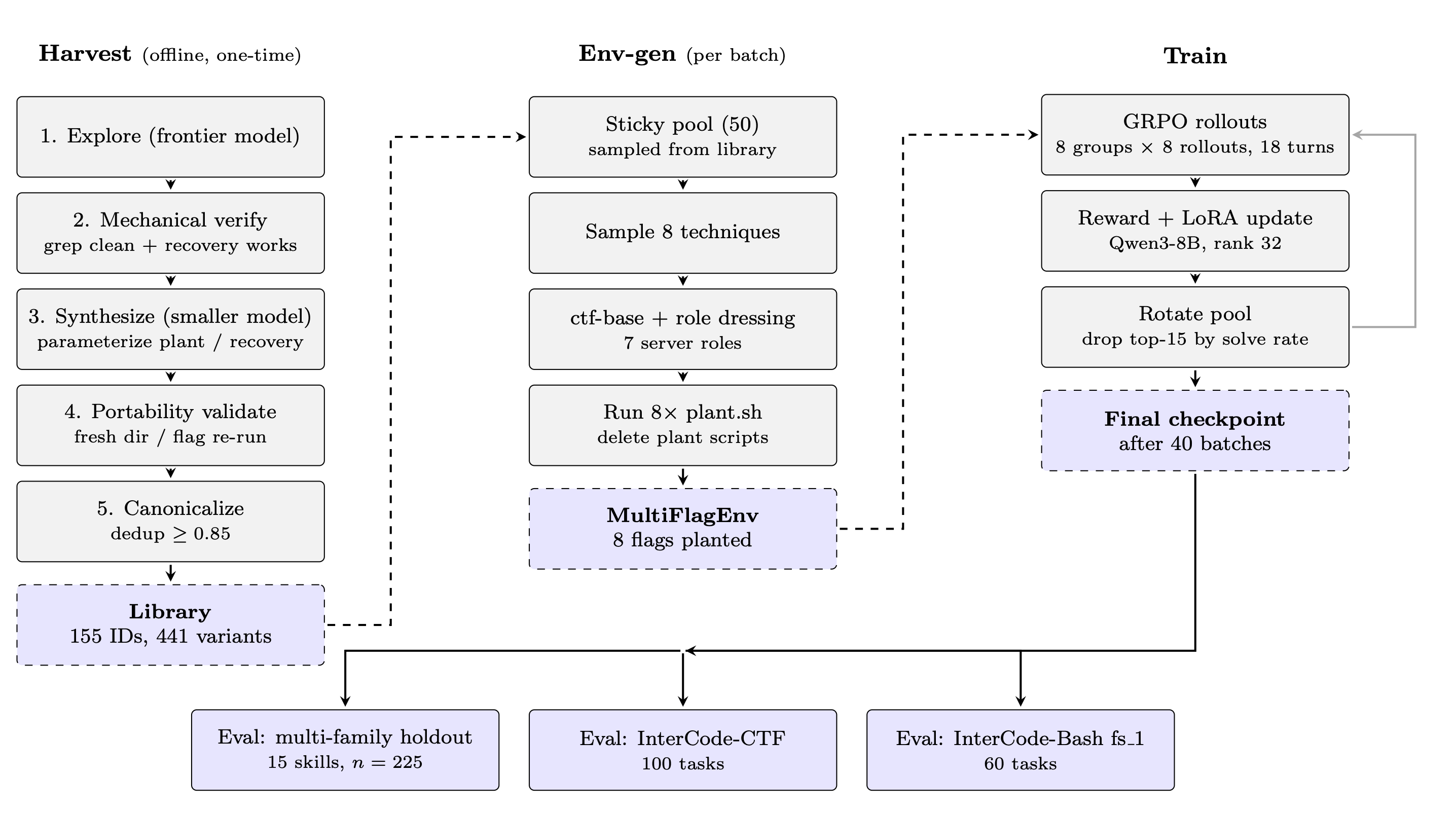
The full unix-ctf loop: harvest a validated library, instantiate multi-flag containers, train with GRPO, then evaluate on held-out and external benchmarks.
Training on unix-ctf
We train on unix-ctf tasks to demonstrate they expose capabilities that can be learned, not as a claim that this is the final or optimal RL recipe or a state-of-the-art Unix agent.
The experiments fine-tune Qwen3-8B with rank-32 LoRA adapters using GRPO. We train two model variants: one starts from the base model, and another first receives a short supervised formatting pass on successful solver trajectories, intended to make the model's tool calls round-trip cleanly through the harness.
Both GRPO variants train for forty batches. Each batch runs eight groups with eight rollouts each, for sixty-four trajectories per batch, with an eighteen-turn budget per rollout.
To demonstrate generalization to unseen unix-ctf tasks, we build a multi-family holdout of fifteen techniques, fifteen fresh trials per technique, and no instance of those held-out techniques in the training pool. Solving this set requires generalization across Unix families rather than memorization of the exact training techniques.
What the Model Learns
On the multi-family holdout, the base Qwen3-8B model solves 11.6% of tasks. GRPO from the base initialization reaches 27.6%. GRPO from the SFT-formatted initialization reaches 43.6%.
The SFT-initialized model also uses the turn budget more efficiently, reducing mean episode length from 17.2 turns for the base model to 12.7 turns. The result suggests that the training surface contains learnable structure, and that learning transfers to techniques that were held out from the training pool.
These results suggest Unix competence is separable enough to target, and the unix-ctf surface is rich enough to teach part of it.
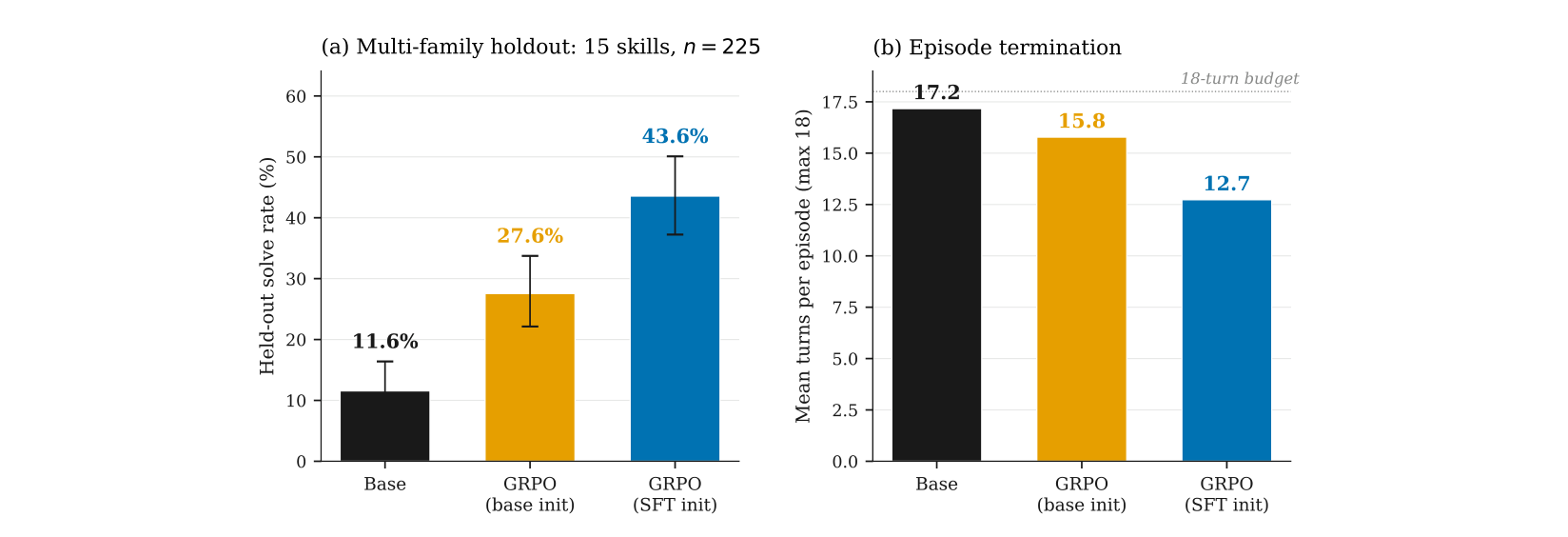
GRPO training improves held-out solve rate, and the SFT-initialized run uses the turn budget more efficiently.
Transfer to InterCode-CTF
To further measure whether unix-ctf teaches generalizable capabilities, we evaluate our trained models on the external InterCode-CTF benchmark.
The base model solves 23 of 100 tasks. GRPO from the base initialization solves 32 of 100. GRPO from the SFT initialization also solves 23 of 100, so aggregate scores do not in isolation suggest a large improvement in InterCode-CTF.
However, the category-level results are more informative. The largest shift is in Forensics, the InterCode-CTF category most aligned with Unix-style artifact recovery. GRPO from the base initialization moves from 1 of 15 Forensics tasks to 6 of 15, a 33 percentage-point gain. Reverse Engineering also improves.
Training on unix-ctf therefore appears to redistribute capability toward the Unix-competence-adjacent parts of the benchmark. Even when the aggregate score stays flat, the model is not solving exactly the same tasks.
The two GRPO initializations also show an interesting result for practitioners. The SFT-initialized run reaches the best multi-family holdout result, but the base-initialized run transfers better to InterCode-CTF. Training reward and internal holdout performance do not fully predict external benchmark movement. Format-adaptation data should be treated as an experimental variable, not a harmless preprocessing step.
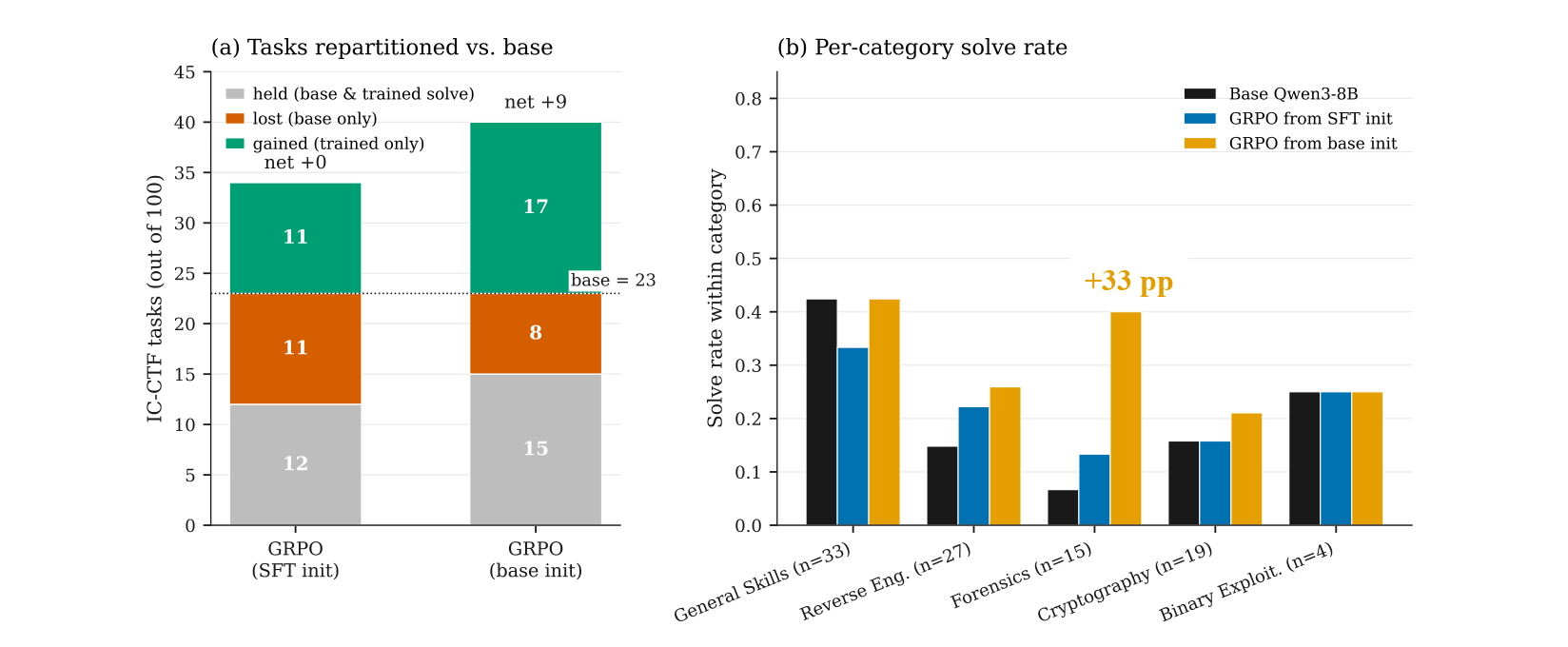
InterCode-CTF results move by category: the strongest shift is in Forensics, the category closest to Unix-style artifact recovery.
Limitations
unix-ctf depends on language models to discover techniques during harvesting. If a technique is poorly represented in the model's prior knowledge, it may never enter the library.
The task format is also narrower than the full measurable distribution of Unix work. Capture-the-flag recovery is a clean way to procedurally generate Unix tasks with verifiable reward, but real Unix work includes administration, debugging, monitoring, repair, performance investigation, deployment, and multi-step maintenance tasks that do not reduce naturally to "find the hidden token."
The experiments are intentionally scoped. The reported training runs are single-seed. The paper does not ablate number of flags, scheduler design, server-role dressing, non-final checkpoints, or alternative reward shapes. The results should be read as evidence that the generated surface is useful and learnable, not as the optimal training recipe.
Conclusion
Terminal competence is not only programming through a terminal. A real Unix system has side channels, metadata, process state, binary conventions, service configuration, shell behavior, and file-format details that do not look like ordinary coding tasks.
By turning those features into procedurally generated CTF environments, unix-ctf creates a focused training and evaluation surface for Unix competence. The generator produces a reusable library at high yield, the multi-flag environments provide dense verifiable reward, and GRPO training on the surface improves held-out Unix-style recovery tasks.
If we want agents that can operate computers, we need training environments that expose the actual structure of those computers. With unix-ctf, we aim to isolate Unix competence in particular by focusing on the operating-system surfaces where agents interface with computers.
Interested in our work? Join us.